Más datos en química
Una información más clara de los resultados experimentales negativos mejoraría la planificación de las reacciones en química
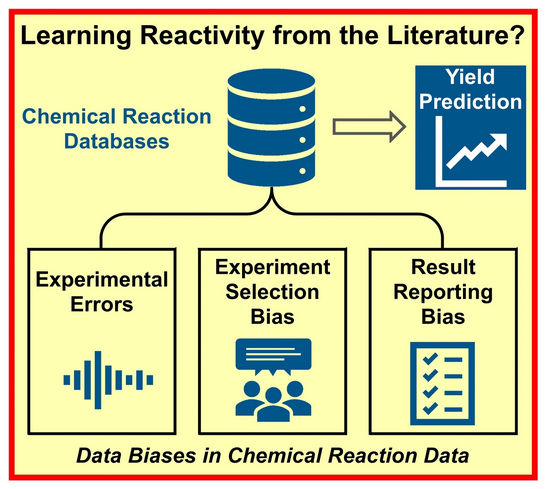
Los investigadores disponen de bases de datos con enormes cantidades de datos experimentales en una gran variedad de disciplinas químicas. Sin embargo, un equipo de investigadores ha descubierto que los datos disponibles no sirven para predecir los rendimientos de nuevas síntesis utilizando la inteligencia artificial (IA) y el aprendizaje automático. Su estudio, publicado en la revista Angewandte Chemie, sugiere que esto se debe en gran parte a la tendencia de los científicos a no informar de los experimentos fallidos.
© Wiley-VCH
Aunque los modelos basados en la IA han tenido especial éxito en la predicción de estructuras moleculares y propiedades de los materiales, devuelven predicciones bastante inexactas en lo que respecta a la información relacionada con el rendimiento de los productos en la síntesis, como han descubierto Frank Glorius y su equipo de investigadores de la Westfälische Wilhelms-Universität Münster (Alemania).
Los investigadores atribuyen este fallo a los datos utilizados para entrenar los sistemas de IA. "Curiosamente, la predicción de los rendimientos de las reacciones (reactividad) es mucho más difícil que la predicción de las propiedades moleculares. Los reactivos, las cantidades, las condiciones y la ejecución experimental determinan el rendimiento, por lo que el problema de la predicción del rendimiento requiere muchos datos", explica Glorius. Así que, a pesar de la enorme cantidad de literatura y resultados disponibles, los investigadores se dieron cuenta de que los datos no son adecuados para predecir con exactitud el rendimiento esperado.
El problema no se debe únicamente a la falta de experimentos. Por el contrario, el equipo identificó tres posibles causas de los datos sesgados. En primer lugar, los resultados de las síntesis químicas pueden ser defectuosos debido a un error experimental. En segundo lugar, cuando los químicos planifican sus experimentos, pueden, consciente o inconscientemente, introducir sesgos basados en la experiencia personal y en la confianza en métodos bien establecidos. Por último, como se cree que sólo las reacciones con un resultado positivo contribuyen al progreso, las reacciones fallidas se comunican con menos frecuencia.
Para averiguar cuál de estos tres factores influye más, Glorius y su equipo alteraron a propósito los conjuntos de datos de cuatro reacciones orgánicas diferentes y de uso común (y, por tanto, ricas en datos). Aumentaron artificialmente el error experimental, redujeron el tamaño de los conjuntos de muestras de datos o eliminaron los resultados negativos de los datos. Sus investigaciones demostraron que el error experimental era el que menos influía en el modelo, mientras que la contribución de la falta de resultados negativos era fundamental.
El grupo espera que estos hallazgos animen a los científicos a informar siempre de los experimentos fallidos, así como de sus éxitos. Esto mejoraría la disponibilidad de datos para el entrenamiento de la IA, lo que, en última instancia, ayudaría a acelerar la planificación y a hacer más eficiente la experimentación. Glorius añade: "El aprendizaje automático en la química (molecular) aumentará la eficiencia de forma espectacular y habrá que ejecutar menos reacciones para lograr un determinado objetivo, por ejemplo, una optimización. Esto capacitará a los químicos y les ayudará a que los procesos químicos -y el mundo- sean más sostenibles".
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Inglés se puede encontrar aquí.
Publicación original

Más noticias del departamento ciencias